大數(shù)據(jù)系統(tǒng)數(shù)據(jù)采集產(chǎn)品的架構分析 聚焦數(shù)據(jù)處理與存儲服務
隨著大數(shù)據(jù)時代的到來,企業(yè)對數(shù)據(jù)采集、處理與存儲的需求日益增長。一個高效的大數(shù)據(jù)系統(tǒng)數(shù)據(jù)采集產(chǎn)品,其核心架構通常包括采集層、處理層和存儲層。本文將重點分析數(shù)據(jù)處理與存儲服務在這一架構中的關鍵作用和實現(xiàn)方式。
一、數(shù)據(jù)采集架構概述
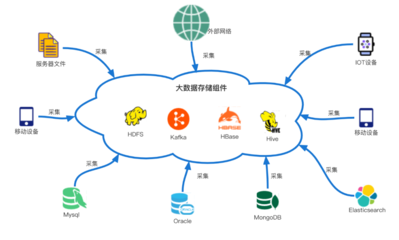
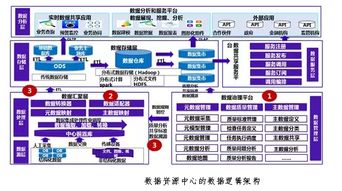
大數(shù)據(jù)系統(tǒng)數(shù)據(jù)采集產(chǎn)品通常采用分層架構:采集層負責從多種數(shù)據(jù)源(如數(shù)據(jù)庫、日志、傳感器、API接口等)收集數(shù)據(jù);處理層對采集到的數(shù)據(jù)進行清洗、轉換、聚合等操作;存儲層則將處理后的數(shù)據(jù)持久化保存,供后續(xù)分析和應用使用。這種架構確保了數(shù)據(jù)從源頭到存儲的完整鏈路,提高了系統(tǒng)的可擴展性和可靠性。
二、數(shù)據(jù)處理服務的關鍵模塊
數(shù)據(jù)處理服務是大數(shù)據(jù)采集產(chǎn)品的核心,主要承擔數(shù)據(jù)質量提升和格式統(tǒng)一的任務。其關鍵模塊包括:
1. 數(shù)據(jù)清洗模塊:去除無效數(shù)據(jù)、處理缺失值和異常值,確保數(shù)據(jù)準確性。
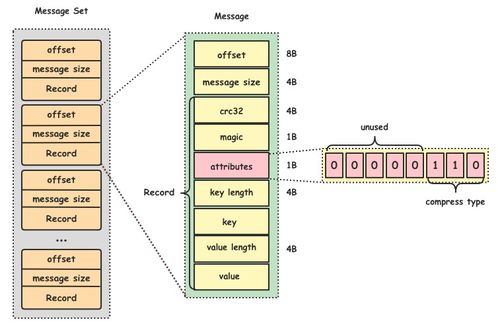
2. 數(shù)據(jù)轉換模塊:將數(shù)據(jù)轉換為目標格式,如JSON、Avro或Parquet,以適應后續(xù)分析需求。
3. 數(shù)據(jù)聚合模塊:對數(shù)據(jù)進行匯總、分組或計算,生成統(tǒng)計指標或聚合視圖。
4. 流處理與批處理模塊:支持實時流處理(如Apache Kafka、Flink)和批量處理(如Spark),滿足不同場景下的時效性要求。
這些模塊通常通過分布式計算框架實現(xiàn),以提高處理效率和容錯能力。
三、數(shù)據(jù)存儲服務的設計要點
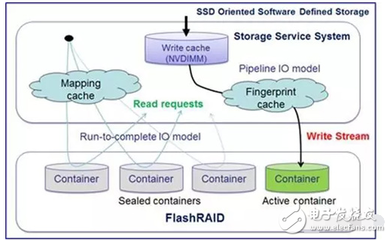
數(shù)據(jù)存儲服務負責持久化數(shù)據(jù),其架構設計需考慮數(shù)據(jù)量、訪問頻率和成本等因素。常見的存儲方案包括:
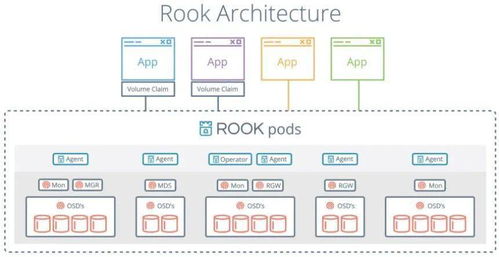
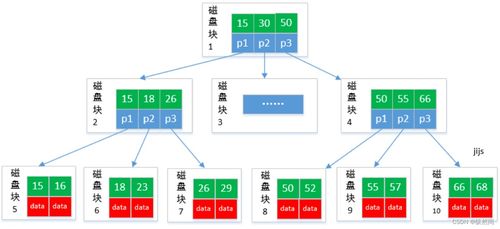
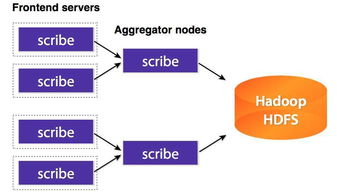
1. 分布式文件系統(tǒng):如HDFS,適用于存儲大規(guī)模非結構化數(shù)據(jù),支持高吞吐量的讀寫操作。
2. NoSQL數(shù)據(jù)庫:如HBase、Cassandra,適合存儲半結構化或非結構化數(shù)據(jù),并提供低延遲的查詢能力。
3. 數(shù)據(jù)湖與數(shù)據(jù)倉庫:數(shù)據(jù)湖(如AWS S3)存儲原始數(shù)據(jù),支持靈活的數(shù)據(jù)探索;數(shù)據(jù)倉庫(如Snowflake、BigQuery)則優(yōu)化了查詢性能,適用于復雜分析。
4. 緩存層:使用Redis或Memcached等工具緩存熱點數(shù)據(jù),減少對后端存儲的壓力。
設計時還需關注數(shù)據(jù)分區(qū)、索引策略和數(shù)據(jù)生命周期管理,以優(yōu)化存儲成本和性能。
四、數(shù)據(jù)處理與存儲的集成實踐
在實際應用中,數(shù)據(jù)處理與存儲服務需緊密集成。例如,通過ETL(提取、轉換、加載)管道將處理后的數(shù)據(jù)直接導入存儲系統(tǒng);或采用Lambda架構,結合批處理和流處理,實現(xiàn)數(shù)據(jù)的高效流動。數(shù)據(jù)治理工具(如Apache Atlas)可幫助跟蹤數(shù)據(jù)血緣,確保數(shù)據(jù)從采集到存儲的透明性和可追溯性。
五、挑戰(zhàn)與未來趨勢
盡管大數(shù)據(jù)采集產(chǎn)品在數(shù)據(jù)處理和存儲方面已取得顯著進展,但仍面臨數(shù)據(jù)安全、實時性要求和成本控制等挑戰(zhàn)。未來,隨著云原生技術和AI驅動的自動化管理的發(fā)展,數(shù)據(jù)處理與存儲服務將更加智能化、彈性化,為企業(yè)提供更高效的數(shù)據(jù)支撐。
數(shù)據(jù)處理和存儲服務是大數(shù)據(jù)系統(tǒng)數(shù)據(jù)采集產(chǎn)品的關鍵組成部分,其架構設計直接影響系統(tǒng)的性能和可靠性。通過優(yōu)化這些服務,企業(yè)能夠更好地挖掘數(shù)據(jù)價值,驅動業(yè)務創(chuàng)新。
如若轉載,請注明出處:http://m.liantao.net.cn/product/12.html
更新時間:2026-05-24 10:22:55